Welcome to meizhangzheng's blog
it-
RabbitMQ架构
RabbitMQ架构
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)。RabbitMQ服务器是用Erlang语言编写的,支持多语言。
1. 场景
1.异步
2.削峰
3.限流
….
2. 架构
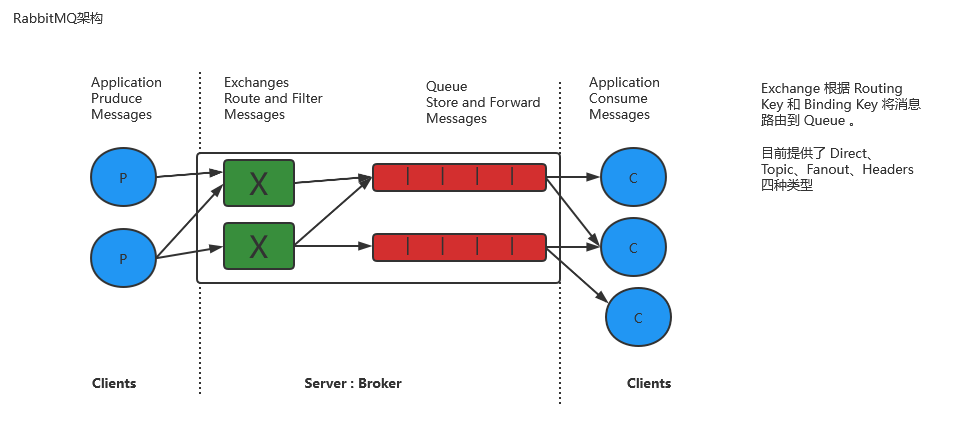
RabbitMQ核心分为Producer、Exchange、Queue、Cusumer块;
-
Kafka集群
Kafka集群
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。Kafka 安装配置
1. 安装Kafka master节点
cd /home/meizhangzheng tar -zxvf kafka_2.13-2.5.0.tgz -C data/ cd data mv kafka_2.13-2.5.0 kafka-2.5.0 mkdir kafka-logs2.配置参数
(1)修改 vi server.properties
broker.id=0 log.dirs=/home/meizhangzheng/data/kafka-logs zookeeper.connect=master:2181,slave1:2181,slave2:2181(2)修改 .bash_profile
export KAFKA_HOME=/home/meizhangzheng/data/kafka-2.5.0 export PATH=$KAFKA_HOME/bin:$PATH3. 分发到各个节点 ( 注意目录 )
[meizhangzheng@master data]$ scp -r /home/meizhangzheng/data/kafka-2.5.0/ ~/data/kafka-logs/ meizhangzheng@slave1:~/data [meizhangzheng@master data]$ scp -r /home/meizhangzheng/data/kafka-2.5.0/ ~/data/kafka-logs/ meizhangzheng@slave2:~/data [meizhangzheng@master data]$ scp -r ~/.bash_profile meizhangzheng@slave1:~/ [meizhangzheng@master data]$ scp -r ~/.bash_profile meizhangzheng@slave2:~/ cd ~ source .bash_profile4. 修改其他配置
master 节点: ssh meizhangzheng@slave1;
目录:/home/meizhangzheng/data/kafka-2.5.0/config(1)修改 vi server.properties
slave1: broker.id=1 slave2: broker.id=25. 启动kafka,各个节点都需要启动
(需要先启动zookeeper,集群组件依赖,单机部署时没必要启动)
[meizhangzheng@master ~]$ kafka-server-start.sh ~/data/kafka-2.5.0/config/server.properties [meizhangzheng@slave1 ~]$ kafka-server-start.sh ~/data/kafka-2.5.0/config/server.properties [meizhangzheng@slave2 ~]$ kafka-server-start.sh ~/data/kafka-2.5.0/config/server.properties6. kafka 的使用 (安装kafka-manager 可查看监控信息)
(1)创建topic 备份数3个、分区数3个
kafka-topics.sh --create --zookeeper master:2181,slave1:2181,slave2:2181 --replication-factor 3 --partitions 3 --topic test Created topic test.(2) 查看topic
kafka-topics.sh --list --zookeeper master:2181,slave1:2181,slave2:2181(3) 生产数据
kafka-console-producer.sh --broker-list master:9092,slave1:9092,slave2:9092 --topic test 输入: a b c d e(4) 验证消息生成成功
kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list master:9092,slave1:9092,slave2:9092 --topic test --time -1 结果: test:0:1 test:1:4 test:2:0 分析:总共5条消息,1条分配到分区0(master)、另外4条被分配到分区1(5)topic消费
kafka-console-consumer.sh --bootstrap-server master:9092,slave1:9092,slave2:9092 --topic test --from-beginning 显示结果: [meizhangzheng@master ~]$ kafka-console-consumer.sh --bootstrap-server master:9092,slave1:9092,slave2:9092 --topic test --from-beginning a b d e c
-
Kafka架构
Kafka架构
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。
1. 场景
xx将监播数据推送(push)到kafka,xx实时拉取(pull) 数据并消费。
2. 架构
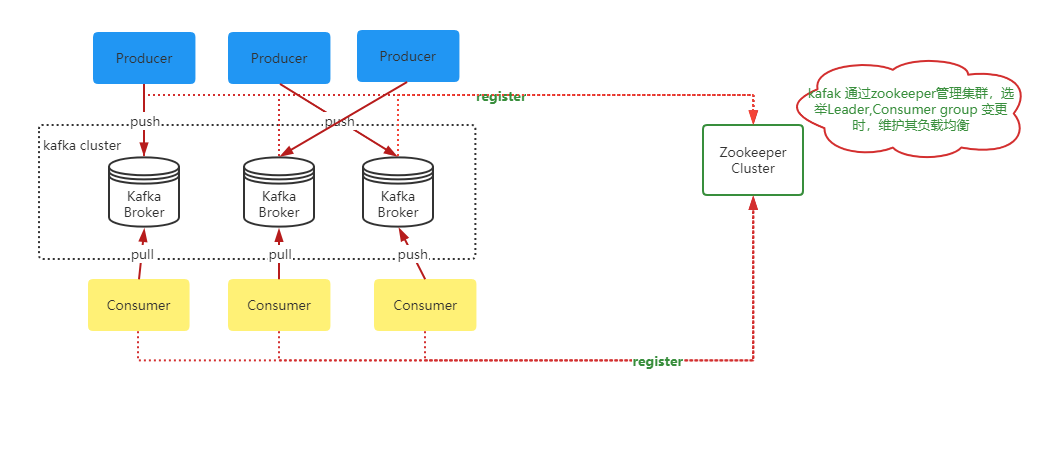
kafka集群一般有若干个Producer、2n+1个Broker、若干个Consuomer 及一个维护集群的zookeeper组成,Producer通过push方式将消息推送到Broker中,Consumer通过pull的方式将消息拉取到并消费。Zookeeper负责管理集群配置,产生Leader,以及消费组变更时重新平衡负载。
名称 作用 Broker 消息中间件处理节点,一个Kafka节点就是一个broker,
一个或者多个Broker可以组成一个Kafka集群Topic Kafka对消息进行归类 Producer 消息生产者,生产消息并发送到Broker的客户端 Consumer 消息消费者,从Broker获取消息并消费的客户端 ConsumerGroup 由一个或多个Consumer组成,一条消息可以发送到多个
ComsumerGroup,同一个GonsumerGroup共享groupIdPartition 一个topic可以分为多个partition,每个partition内部是有序的
-
Zookeeper集群
Zookeeper集群
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
Zookeeper 安装
Master 节点操作:
cd /home/meizhangzheng wget https://downloads.apache.org/zookeeper/zookeeper-3.6.0/apache-zookeeper-3.6.0-bin.tar.gz1. 解压 zookeeper 安装包
#目录: /home/meizhangzheng tar -zxvf apache-zookeeper-3.6.0-bin.tar.gz -C ~/data/ cd /home/meizhangzheng/data mv apache-zookeeper-3.6.0-bin zookeeper-3.6.02. 配置zookeeper
cd /home/meizhangzheng/data/zookeeper-3.6.0/conf vi zoo.cfg dataDir=/home/meizhangzheng/data/zk_data dataLogDir=/home/meizhangzheng/data/zk_log server.1=master:2888:3888 server.2=slave1:2888:3888 server.3=slave2:2888:38883. 填写myid,master ,slave1,slave2 分别填写1,2,3 (每台主机填写一个)
cd /home/meizhangzheng mkdir -p /home/meizhangzheng/data/zk_data mkdir -p /home/meizhangzheng/data/zk_log cd /home/meizhangzheng/data/zk_data sudo vim myid4.复制到其他节点
scp -r ~/data/zookeeper-3.6.0/ meizhangzheng@slave1:~/data scp -r ~/data/zookeeper-3.6.0/ meizhangzheng@slave2:~/data scp -r ~/data/zk_data/ meizhangzheng@slave1:~/data scp -r ~/data/zk_data/ meizhangzheng@slave2:~/data5. 启动校验
#5.1 启动 zkServer.sh start #5.2 查看状态 zkServer.sh status #5.3 查看当前进程 jps #5.4 查看日志 cat zookeeper.out zkServer.sh start-foreground #5.5 停止 zkServer.sh stop6.注意事项
– 日志信息 (1)mkdir: cannot create directory ‘/home/meizhangzheng/data/zookeeper-3.6.0/bin/../logs’: Permission denied
#设置日志环境变量 dataLogDir=/home/meizhangzheng/data/zk_log
-
Zookeeper架构
Zookeeper架构
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
1. Zookeeper数据模型
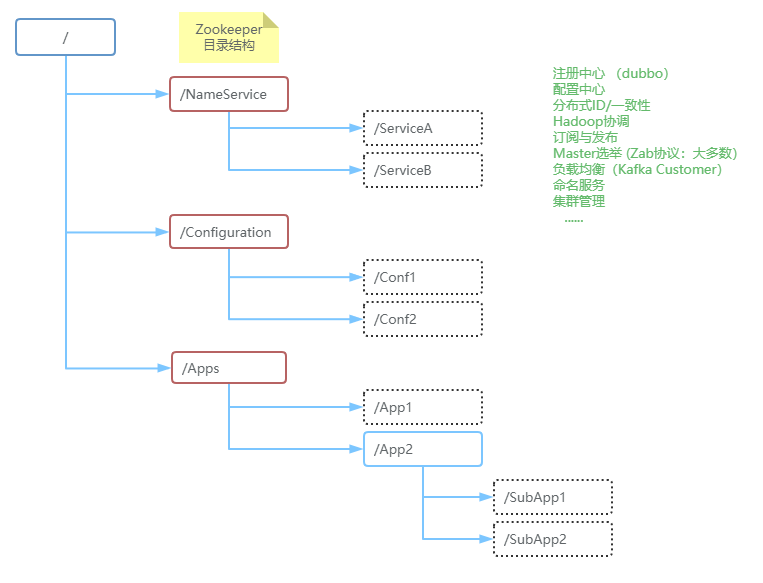
自客户端的每个更新请求,ZooKeeper 都会分配一个全局唯一的递增编号
2. Zookeeper 选举模型

Leader :既可以为客户端提供写服务又能提供读服务,Follower、Observer 提供只读服务
Follower:参与Leader投票选举,对外提供服务
Observer:不选与Leader选举投票过程,只同步leader状态,及对外提供服务。
Client:请求发起方
-
Spark集群环境搭建
Spark集群
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。
spark环境安装、测试
Spark安装配置
2.1 下载Spark
由系统提供的hadoop版本预先构建 下载地址 https://mirror.bit.edu.cn/apache/spark/spark-2.4.5/spark-2.4.5-bin-without-hadoop.tgz
cd /home/meizhangzheng wget https://mirror.bit.edu.cn/apache/spark/spark-2.4.5/spark-2.4.5-bin-without-hadoop.tgz2.2 安装spark,解压到data目录
tar -zxvf spark-2.4.5-bin-without-hadoop.tgz -C /home/meizhangzheng/data/2.3 配置spark 环境
spark中涉及到的配置文件: ${SPARK_HOME}/conf/spark-env.sh ${SPARK_HOME}/conf/slaves ${SPARK_HOME}/conf/spark-defaults.conf2.3.1 spark-env.sh 配置
(1) cd /home/meizhangzheng/data/spark-2.4.5-bin-without-hadoop/conf (2) cp spark-env.sh.template spark-env.sh (3) 配置变量 JAVA_HOME=/home/meizhangzheng/jdk1.8.0_231 SCALA_HOME=/home/meizhangzheng/data/scala-2.13.0 SPARK_MASTER_IP=192.168.1.10 HADOOP_CONF_DIR=/home/meizhangzheng/data/hadoop-2.10.0/etc/hadoop ######### data store dir # shuffled以及RDD的数据存放目录,用于写中间数据 SPARK_LOCAL_DIRS=/home/meizhangzheng/data/spark_data ######### worker process dir,contain log ,tmp store space。 ######### worker端进程的工作目录,包括worker的日志以及临时存储空间,默认:${SPARK_HOME}/work SPARK_WORKER_DIR=/home/meizhangzheng/data/spark_data/spark_works -- 特殊配置 HADOOP_HOME=/home/meizhangzheng/data/hadoop-2.10.0 export SPARK_DIST_CLASSPATH=$(/home/meizhangzheng/data/hadoop-2.10.0/bin/hadoop classpath) (4) 创建 spark_works 目录 mkdir -p /home/meizhangzheng/data/spark_data/spark_works2.3.2 slaves 配置
(1) cd /home/meizhangzheng/data/spark-2.4.5-bin-without-hadoop/conf (2) scp slaves.template slaves 将localhost 修改为 master slave1 slave2 将从这三台主机启动spark程序。2.3.3 spark-default.conf 配置
(1) cd /home/meizhangzheng/data/spark-2.4.5-bin-without-hadoop/conf (2) scp spark-defaults.conf.template spark-defaults.conf ####### add config info spark.master spark://master:7077 spark.serializer org.apache.spark.serializer.KryoSerializer spark.eventLog.enabled true spark.eventLog.dir file:///data/spark_data/history/event-log spark.history.fs.logDirectory file:///data/spark_data/history/spark-events spark.eventLog.compress true[2020-07-16] 备注:file:///data/spark_data/history/event-log 该目录 是在 /data 目录下 [meizhangzheng@master /]$ ll total 24 lrwxrwxrwx. 1 root root 7 Dec 14 2019 bin -> usr/bin dr-xr-xr-x. 5 root root 4096 Dec 14 2019 boot drwxr-xr-x 3 meizhangzheng meizhangzheng 24 Jul 16 06:54 data drwxr-xr-x 20 root root 3300 Jul 14 06:56 dev drwxr-xr-x. 145 root root 8192 Jul 16 06:45 etc drwxr-xr-x. 3 root root 27 Dec 31 2019 home lrwxrwxrwx. 1 root root 7 Dec 14 2019 lib -> usr/lib lrwxrwxrwx. 1 root root 9 Dec 14 2019 lib64 -> usr/lib64 drwxr-xr-x. 2 root root 6 Apr 11 2018 media drwxr-xr-x. 2 root root 6 Apr 11 2018 mnt drwxr-xr-x. 3 root root 16 Dec 14 2019 opt dr-xr-xr-x 254 root root 0 Jul 14 06:56 proc dr-xr-x---. 7 root root 267 Apr 30 08:09 root drwxr-xr-x 41 root root 1220 Jul 16 06:47 run lrwxrwxrwx. 1 root root 8 Dec 14 2019 sbin -> usr/sbin drwxr-xr-x. 2 root root 6 Apr 11 2018 srv dr-xr-xr-x 13 root root 0 Jul 16 07:43 sys drwxrwxrwt. 22 root root 4096 Jul 16 07:53 tmp drwxr-xr-x. 13 root root 155 Dec 14 2019 usr drwxr-xr-x. 21 root root 4096 Dec 14 2019 var [meizhangzheng@master /]$2.3.4 配置spark 环境变量
(1) cd /home/meizhangzheng (2) sudo vim .bash_profile ####### 2020.04.27 add spark path export SPARK_HOME=/home/meizhangzheng/data/spark-2.4.5-bin-without-hadoop export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH2.3.5 分发spark 到slave1、slave2节点
(1) scp -r data/spark-2.4.5-bin-without-hadoop/ meizhangzheng@slave1:~/data/ (2) scp -r data/spark-2.4.5-bin-without-hadoop/ meizhangzheng@slave2:~/data/ (3) scp -r .bash_profile meizhangzheng@slave1:~ (4) scp -r .bash_profile meizhangzheng@slave2:~ (5) 使slave1、slav2 .bash_profile配置生效 ssh meizhangzheng@slave1 source .bash_profile ssh meizhangzheng@slave1 source .bash_profile2.4.1 启动验证
<1.启动服务 start-master.sh start-slaves.sh <2.查看集群 http://192.168.1.10:8080 <3·. 出现 spark-2.4.5-bin-without-hadoop 启动报错 failed to launch: nice -n 0 log jar 未找到的异常参考文档
参考spark-2.4.3-bin-without-hadoop的安装
在spark-env.sh 中添加如下配置 HADOOP_HOME=/home/meizhangzheng/data/hadoop-2.10.0 export SPARK_DIST_CLASSPATH=$(/home/meizhangzheng/data/hadoop-2.10.0/bin/hadoop classpath) #不添加,就会报错
ERROR spark.SparkContext: Error initializing SparkContext. java.io.FileNotFoundException: File file:/data/spark_data/history/event-log does not exist解决办法:创建文件夹
/data/spark_data/history/event-log /data/spark_data/history/spark-events
[meizhangzheng@slave2 ~]$ mkdir -p /data/spark_data/history/event-log 注意: 该目录是指 如下目录: [meizhangzheng@salve1 /]$ pwd / [meizhangzheng@salve1 /]$ total 24 lrwxrwxrwx. 1 root root 7 Dec 14 2019 bin -> usr/bin dr-xr-xr-x. 5 root root 4096 Dec 14 2019 boot drwxr-xr-x 3 meizhangzheng meizhangzheng 24 Jul 16 07:40 data drwxr-xr-x 20 root root 3300 Jul 14 06:56 dev drwxr-xr-x. 145 root root 8192 Jul 16 06:45 etc drwxr-xr-x. 3 root root 27 Dec 14 2019 home lrwxrwxrwx. 1 root root 7 Dec 14 2019 lib -> usr/lib lrwxrwxrwx. 1 root root 9 Dec 14 2019 lib64 -> usr/lib64 drwxr-xr-x. 2 root root 6 Apr 11 2018 media drwxr-xr-x. 2 root root 6 Apr 11 2018 mnt drwxr-xr-x. 3 root root 16 Dec 14 2019 opt dr-xr-xr-x 237 root root 0 Jul 14 06:56 proc dr-xr-x---. 7 root root 267 May 8 07:18 root drwxr-xr-x 41 root root 1220 Jul 16 06:45 run lrwxrwxrwx. 1 root root 8 Dec 14 2019 sbin -> usr/sbin drwxr-xr-x. 2 root root 6 Apr 11 2018 srv dr-xr-xr-x 13 root root 0 Jul 16 08:03 sys drwxrwxrwt. 17 root root 4096 Jul 16 08:03 tmp drwxr-xr-x. 13 root root 155 Dec 14 2019 usr drwxr-xr-x. 21 root root 4096 Dec 14 2019 var未使用 [meizhangzheng@master tmp]$ hadoop fs -touchz /data/spark_data/history/event-log [meizhangzheng@master tmp]$ hadoop fs -touchz /data/spark_data/history/spark-events
- Books 4
- Windows/Linux/Mac 8
- 实战 18
- 工具 12
- 网络 2
- 协议 1
- 工具/Java 1
- Git 1
- Nginx 1
- Shell 1
- Nginx实战 1
- Python实战 1
- Maven 1
- 正则表达式 1
- Java 12
- 操作符 1
- IO 3
- SPI 1
- Test 1
- DB 13
- MySQL 10
- Redis 2
- MongoDB 2
- 基础 1
- WEB安全 1
- WEB 2
- 前端 4
- 跨域 1
- HTTPS 1
- 安全 1
- 证书 1
- 集合 5
- ConcurrentHashMap 1
- 容器 9
- 性能优化 2
- Tomcat 1
- 数据结构 5
- 堆 1
- 栈 1
- 队列 1
- 树 2
- 链表 1
- 算法 3
- 二分法 1
- 排序 1
- 扩展 1
- Lambda 1
- 设计模式 2
- 框架 7
- Spring 1
- Mybatis 2
- Mybatis-Plus 1
- SpringBoot 5
- Nacos 1
- 微服务 4
- Eureka 3
- 高并发 9
- 分布式 1
- 安全性 3
- Happens-Before 1
- Synchronized 1
- Atomic 1
- Collection 1
- Lock 3
- JVM 2
- Docker 9
- 安装 2
- Dockerfile 1
- Kafka 3
- Jenkins 1
- K8s 2
- CNCF 1
- 云原生 1
- 大数据 27
- Hive 1
- Hadoop 5
- NTP 3
- Flink 2
- FTP 1
- 数据仓库 1
- ETL 3
- Kettle 2
- 开放平台 1
- 数据中台 1
- Spark 6
- Zookeeper 2
- Rabbit 1
- Flume 1
- RDD 1
- DataFrame 1
- DataSet 1
- 解决方案 1
- 高级 1
- 组件 1
- JS 1
- Tool 1
- 报表 1
- kkFileView 1