Welcome to meizhangzheng's blog
it-
解决方案
解决方案
一. 基本
1. 采集
1.1 线上
线上(接口、表、库 …)
1.2 导入导出
线下(导入、导出)
easyexcel(线下采集) easypoi (WLH) poi-tl (桥梁)
-
Spark总结
一、Spark RDD DataFrame DataSet 分析
1. 来源
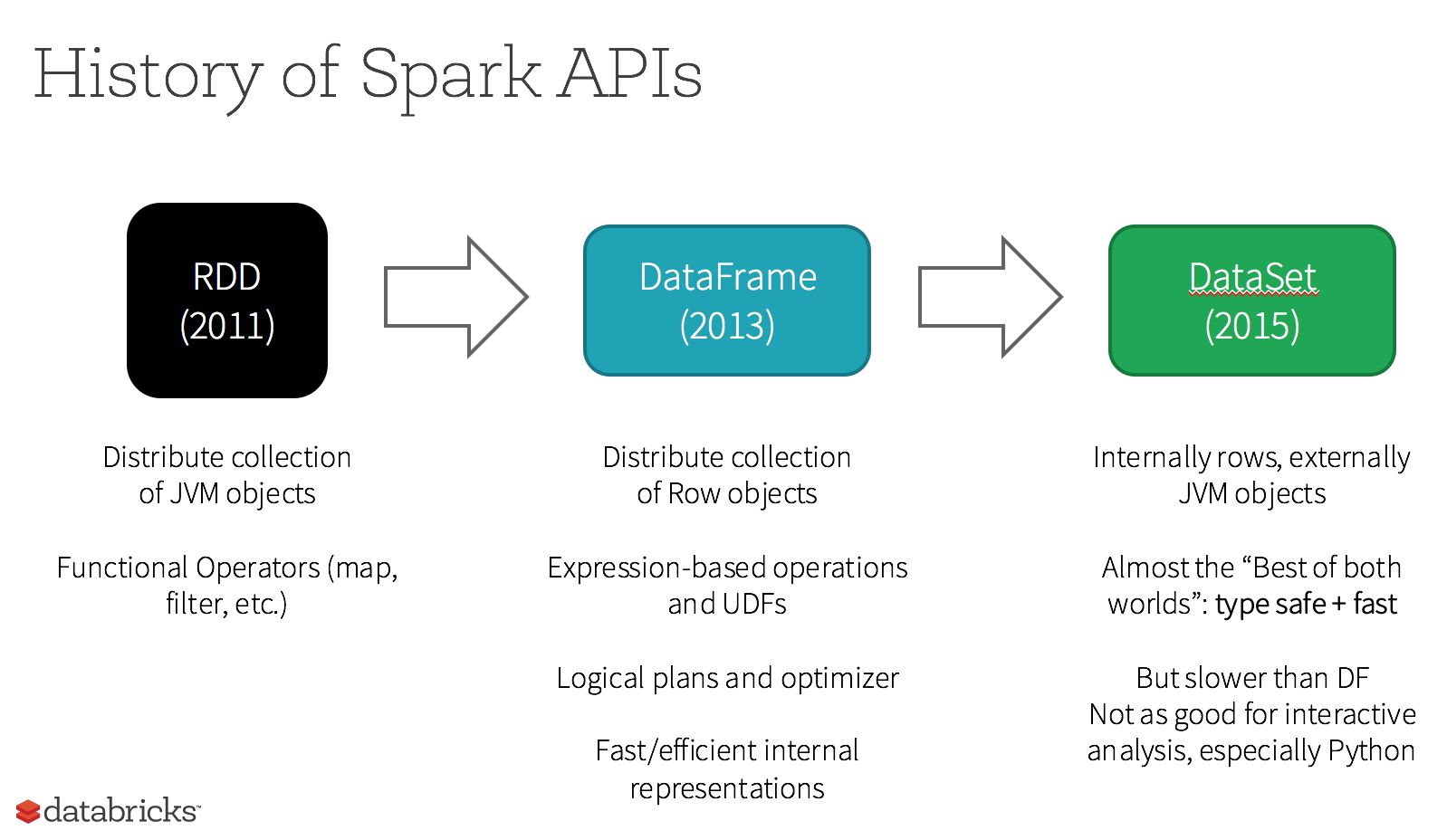
2. 转换
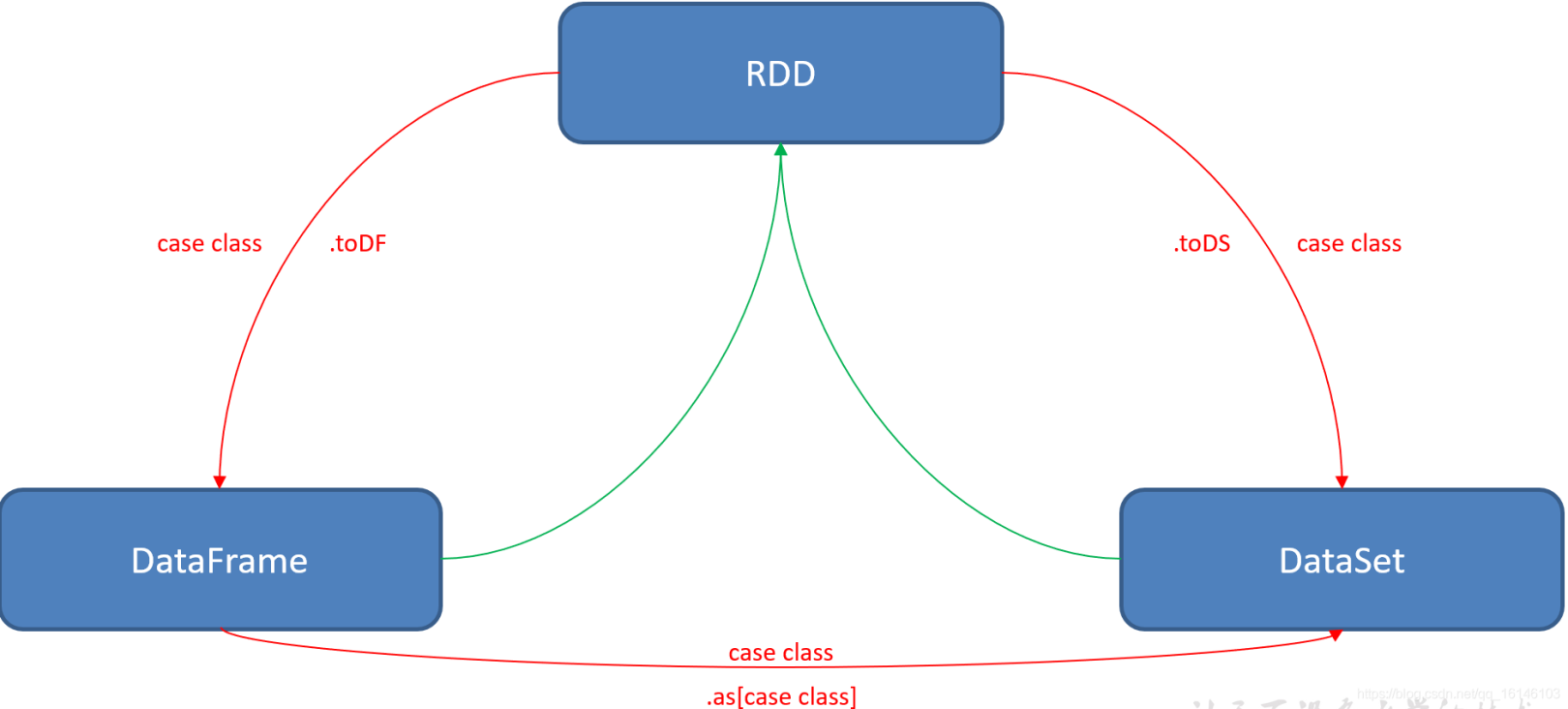
3. 区别
数据集名称 创建 序列化 类型 是否带有
元信息检测时机 RDD file、现有RDD
scala创建专用的Encoder
编码器无 无 运行时 DataFrame 能相互转换 使用Java
序列化或Kryo弱类型(untypedrel) schema 运行时 DataSet SparkSession … 专用的Encoder
编码器强类型(typedrel) schema 编译时 4. 优缺点
数据集名称 优点 缺点 RDD 1.强大,内置很多函数操作,group,map,
filter等,方便处理结构化或非结构化数据
2.面向对象编程,直接存储的java对象,类型转化也安全1.由于它基本和hadoop一样万能的,
因此没有针对特殊场景的优化,
比如对于结构化数据处理相对于sql来比非常麻烦
2.默认采用的是java序列号方式,序列化结果比较
大,而且数据存储在java堆内存中,
导致gc比较DataFrame 1.结构化数据处理非常方便,支持Avro, CSV, elastic search,
and Cassandra等kv数据,也支持HIVE tables, MySQL等传统数据表
2.有针对性的优化,由于数据结构元信息spark已经保存,
序列化时不需要带上元信息,大大的减少了序列化大小,
而且数据保存在堆外内存中,减少了gc次数。
3.hive兼容,支持hql,udf等1.编译时不能类型转化安全检查,
运行时才能确定是否有问题
2.对于对象支持不友好,
rdd内部数据直接以java对象存储,
dataframe内存存储的是row对象而不能是自定义对象DataSet 1.dataset整合了rdd和dataframe的优点,支持结构化和非结构化数据
2.和RDD一样,支持自定义对象存储
3.和dataframe一样,支持结构化数据的sql查询
4.采用堆外内存存储,gc友好
5.类型转化安全,支持编译器解码,代码友好
6.官方建议使用dataset
-
SparkDataSet实战
Spark DataSet
一、Spark DataSet 编程
1.1 什么是 Spark DataSet?
Dataset是一个分布式的数据集。 Dataset是Spark 1.6开始新引入的一个接口,它结合了RDD API的很多优点(包括强类型,支持lambda表达式等),以及Spark SQL的优点(优化后的执行引擎)。Dataset可以通过JVM对象来构造,然后通过transformation类算子(map,flatMap,filter等)来进行操作。Scala和Java的API中支持Dataset,但是Python不支持Dataset API。不过因为Python语言本身的天然动态特性,Dataset API的不少feature本身就已经具备了(比如可以通过row.columnName来直接获取某一行的某个字段)。R语言的情况跟Python也很类似。 Dataframe就是按列组织的Dataset。 在逻辑概念上,可以大概认为Dataframe等同于关系型数据库中的表,或者是Python/R语言中的data frame,但是在底层做了大量的优化。Dataframe可以通过很多方式来构造:比如结构化的数据文件,Hive表,数据库,已有的RDD。Scala,Java,Python,R等语言都支持Dataframe。在Scala API中,Dataframe就是Dataset[Row]的类型别名。在Java中,需要使用Dataset<Row>来代表一个Dataframe。
-
Spark DataFrame实战
Spark DataFrame
一、Spark DataFrame SQL 编程
1.1 什么是 Spark DataFrame & SQL?
Spark DataFrame 是一个带有列名称的分布式数据集,类似于关系型数据库中的一张表,可以通过结构化的数据文件,Hive中的表,外部数据库以及已经存在的RDD得到。 Spark SQL 是使用 SQL 或 HiveQL 语法编写 SQL 语句,来执行计算任务。1.2 Spark DataFrame & SQL 引入动机?
1)Spark DataFrame & SQL 执行效率相比 RDD 更高 2)Spark DataFrame & SQL 代码更简洁 3)Spark DataFrame & SQL 带有自动优化程序引擎 ### 1.3 Spark DataFrame 与 RDD区别DataFrame = RDD[Row] + shcema
-
SparkRDD实战
SparkRDD
1.基本概念
1.1 什么是 RDD?
RDD(Resilient Distributed Datasets):一个弹性分布式数据集, Spark中的基本抽象。 代表一个不变(只读)的、可以并行操作的元素的分区集合。 Spark中原生的RDD支持从以下三种方式创建:从scala集合中创建、从文件系统中创建、现有RDD的transform操作创建。1.2. Spark RDD 示例
#1. 进入 tmp目录: cd /home/meizhangzheng/hadoop/tmp #2. 创建多级目录 hadoop fs -mkdir -p /data/tmp #3. 创建源数据文件 hadoop fs -touchz /data/tmp/word.txt #4.查看目录 hdfs dfs -ls /data/tmp #5. 查看文件内容 hdfs dfs -cat /data/tmp/word.txt #6. 将本地文件复制到hdfs上命令 hadoop fs -put word.txt /data/tmp/word.txt bout yun hello word hello spark #注: 如果文件存在则覆盖,添加 -f hadoop fs -put -f word.txt /data/tmp/word.txt #7.开始统计单词
-
Flume集群
Flume
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Flume 安装配置
wget http://www.apache.org/dyn/closer.lua/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz cd /home/meizhangzheng1. 解压
tar -zxvf apache-flume-1.9.0-bin.tar.gz -C ~/data cd data mv apache-flume-1.9.0-bin flume-1.9.02. 添加环境变量配置信息:
– 2020.05.09 add flume path
export FLUME_HOME=/home/meizhangzheng/data/flume-1.9.0 export PATH=$FLUME_HOME/bin:$PATH3.flum 配置信息:
cd /home/meizhangzheng/data/flume-1.9.0/conf touch test.properties vi test.properties3.1 add config
agent.sources = s1 agent.channels = c1 agent.sinks = k1 agent.sources.s1.type = org.apache.flume.source.taildir.TaildirSource agent.sources.s1.channels = c1 agent.sources.s1.positionFile = /home/meizhangzheng/data/flume-1.9.0/test/taildir_position.json agent.sources.s1.filegroups = f1 agent.sources.s1.filegroups.f1 = /home/meizhangzheng/data/testlog/.*.log agent.sources.s1.batchSize = 4000 agent.channels.c1.type = file agent.channels.c1.checkpointDir = /home/meizhangzheng/data/flume-1.9.0/test/checkpoint agent.channels.c1.dataDirs = /home/meizhangzheng/data/flume_data agent.channels.c1.keep-alive = 6 agent.sinks.k1.channel = c1 agent.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink agent.sinks.k1.kafka.topic=test agent.sinks.k1.kafka.bootstrap.servers = 192.168.1.10:9092,192.168.1.20:9092,192.168.1.30:9092 agent.sinks.k1.kafka.producer.acks = 1 agent.sinks.k1.kafka.flumeBatchSize = 10003.2 创建测试目录
需要在/home/meizhangzheng/data/flume-1.9.0 创建test目录
cd /home/meizhangzheng/data/flume-1.9.0 mkdir test3.3 创建日志目录
在data 目录创建flume 日志目录
cd /home/meizhangzheng/data mkdir testlog4. agent启动flume
4.1 需要启动zookeeper 、kafka 集群
zkServer.sh start kafka-server-start.sh ~/data/kafka-2.5.0/config/server.properties4.2 启动 主题为 test的kafka消费
kafka-console-consumer.sh --bootstrap-server master:9092,slave1:9092,slave2:9092 --topic test --from-beginning4.3 启动flume
sh flume-ng agent -c conf -f ~/data/flume-1.9.0/conf/test.properties --name agent -Dflume.root.logger=WARN,console4.4 进入testlog目录,然后写test.log文件,同时查看该文件的信息是否被消费
cd /home/meizhangzheng/data/testlog echo "hello" >> test.log4.5 打开 监听 test主题的进程: 查看结果
[meizhangzheng@master ~]$ kafka-console-consumer.sh --bootstrap-server master:9092,slave1:9092,slave2:9092 --topic test --from-beginning a b d e hello c mzz Sat May 9 07:51:32 CST 2020 Sat May 9 07:52:28 CST 2020 source:console source:test.log file
Recent Posts
Categories
- Books 4
- Windows/Linux/Mac 8
- 实战 18
- 工具 12
- 网络 2
- 协议 1
- 工具/Java 1
- Git 1
- Nginx 1
- Shell 1
- Nginx实战 1
- Python实战 1
- Maven 1
- 正则表达式 1
- Java 12
- 操作符 1
- IO 3
- SPI 1
- Test 1
- DB 13
- MySQL 10
- Redis 2
- MongoDB 2
- 基础 1
- WEB安全 1
- WEB 2
- 前端 4
- 跨域 1
- HTTPS 1
- 安全 1
- 证书 1
- 集合 5
- ConcurrentHashMap 1
- 容器 9
- 性能优化 2
- Tomcat 1
- 数据结构 5
- 堆 1
- 栈 1
- 队列 1
- 树 2
- 链表 1
- 算法 3
- 二分法 1
- 排序 1
- 扩展 1
- Lambda 1
- 设计模式 2
- 框架 7
- Spring 1
- Mybatis 2
- Mybatis-Plus 1
- SpringBoot 5
- Nacos 1
- 微服务 4
- Eureka 3
- 高并发 9
- 分布式 1
- 安全性 3
- Happens-Before 1
- Synchronized 1
- Atomic 1
- Collection 1
- Lock 3
- JVM 2
- Docker 9
- 安装 2
- Dockerfile 1
- Kafka 3
- Jenkins 1
- K8s 2
- CNCF 1
- 云原生 1
- 大数据 27
- Hive 1
- Hadoop 5
- NTP 3
- Flink 2
- FTP 1
- 数据仓库 1
- ETL 3
- Kettle 2
- 开放平台 1
- 数据中台 1
- Spark 6
- Zookeeper 2
- Rabbit 1
- Flume 1
- RDD 1
- DataFrame 1
- DataSet 1
- 解决方案 1
- 高级 1
- 组件 1
- JS 1
- Tool 1
- 报表 1
- kkFileView 1
Tags